728x90
반응형
비트(bit)와 바이트(byte)
- 컴퓨터는 모든 데이터를 2진수로 표현하고 처리한다.
- 비트(bit)란 컴퓨터가 데이터를 처리하기 위해 사용하는 데이터의 최소 단위다. 이러한 비트에는 2진수의 값(0과 1)을 단 하나만 저장할 수 있다.
- 바이트(byte)란 위와 같은 비트가 8개 모여서 구성되며, 한 문자를 표현할 수 있는 최소 단위다.
바이트 저장 순서(byte order)
- 컴퓨터는 데이터를 메모리에 저장할 때 바이트(byte) 단위로 나눠서 저장한다. 하지만 컴퓨터가 저장하는 데이터는 대게 32비트(4바이트)나 64비트(8바이트)로 구성된다. 따라서 이렇게 연속되는 바이트를 순서대로 저장해야 하는데, 이것을 바이트 저장 순서(byte order)라고 한다.
- 이때 바이트가 저장되는 순서에 따라 ① 빅 엔디안(big endian) ② 리틀 엔디안(little endian)과 같이 두 가지 방식으로 나눌 수 있다.
빅 엔디안(big endian)
- 빅 엔디안 방식은 낮은 주소에 데이터의 높은 바이트(MSB, Most Significant Bit)부터 저장하는 방식이다.
- 이 방식은 평소 우리가 숫자를 사용하는 선형 방식과 같은 방식이다. 따라서 메모리에 저장된 순서 그대로 읽을 수 있으며, 이해하기가 쉽다는 장점을 가지고 있다.
- SPARC을 포함한 대부분의 RISC CPU 계열에서는 이 방식으로 데이터를 저장한다.
// 2비트 크기의 정수
0x12345678
// 이 정수는 각각 다음과 같이 1바이트값 4개로 구성
0x12, 0x34, 0x56, 0x78
리틀 엔디안(little endian)
- 리틀 엔디안 방식은 낮은 주소에 데이터의 낮은 바이트(LSB, Least Significant Bit)부터 저장하는 방식이다.
- 이 방식은 평소 우리가 숫자를 사용하는 선형 방식과는 반대로 거꾸로 읽어야 한다.
- 대부분의 인텔 CPU 계열에서는 이 방식으로 데이터를 저장한다.
- 앞서 예를 든 정수 "0x12345678"를 리틀 엔디안 방식으로 저장하면 다음 그림과 같이 저장된다.
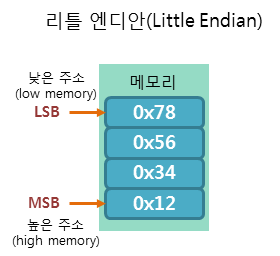
빅 엔디안 vs 리틀 엔디안
- 빅 엔디안과 리틀 엔디안은 단지 저장해야 할 큰 데이터를 어떻게 나누어 저장하는가에 따른 차이일 뿐, 어느 방식이 더 우수하다고는 단정할 수 없다.
- 물리적으로 데이터를 조작하거나 산술 연산을 수행할 때에는 리틀 엔디안 방식이 더 효율적이다. 하지만 데이터의 각 바이트를 배열처럼 취급할 때에는 빅 엔디안 방식이 더 적합하다.
- 현재 대부분의 시스템은 인텔 기반의 윈도우이므로 리틀 엔디안 방식을 사용하고 있을 것이지만 네트워크를 통해 데이터를 전송할 때에는 빅 엔디안 방식이 사용된다. 따라서 인텔 기반의 시스템에서 소켓 통신을 할 때는 바이트 순서에 신경을 써서 데이터를 전달해야 한다.
바이트 저장 순서의 확인
int i;
int test = 0x12345678;
char* ptr = (char*)&test; // 1 바이트만을 가리키는 포인터를 생성함.
for (i = 0; i < sizeof(int); i++) {
printf("%x", ptr[i]); // 1 바이트씩 순서대로 그 값을 출력함.
}
// 78563412 - 결과가 이렇다면 리틀 엔디안 방식의 시스템
// 12345678 - 결과가 이렇다면 빅 엔디안 방식의 시스템
비트 단위 연산(bitwise operation)
- 컴퓨터는 모든 데이터를 비트(bit) 단위로 표현하고 처리한다.
- 과거에는 개발자가 직접 비트 단위 연산을 사용하여, 복잡한 연산을 훨씬 더 빠르고 효율적으로 수행해야만 했다. 하지만 하드웨어의 발달로 이제는 비트 단위까지 생각하지 않더라도, 충분히 빠른 프로그램을 작성할 수 있게 되었다.
- 그러나 아직도 하드웨어 관련 프로그래밍이나 시스템 프로그래밍 등 제한된 자원을 가진 시스템을 위한 프로그램에서는 비트 단위의 연산이 자주 사용되고 있다. 이러한 비트 단위 연산을 통해 사용되는 메모리 공간을 줄이거나, 성능의 향상을 기대할 수 있기 때문이다.
비트 연산자
- 비트 연산자는 비트(bit) 단위로 논리 연산을 할 때 사용하는 연산자다. 또한 왼쪽이나 오른쪽으로 전체 비트를 이동시킬 때에도 사용한다.

비트 연산자 진리표
- 비트 연산자 진리표란 각 비트의 값에 따라 얻을 수 있는 가능한 비트값을 표로 나타낸 것을 가리킨다.

비트 NOT 연산자
- 비트 NOT 연산자는 주어진 비트가 1이면 0으로, 0이면 1로 반전시켜 1의 보수로 만들어 준다. 이러한 비트 NOT 연산자는 피연산자가 단 하나뿐인 단항 연산자다.
- 아래 예제처럼 비트 NOT 연산은 부호 비트도 반전시키므로, 결괏값이 음수로 변경된다.
int x = 7; // 00000000 00000000 00000000 00000111
printf("%d", ~x); // 11111111 11111111 11111111 11111000 : -8
// -8비트 AND 연산자
- 비트 AND 연산자는 두 개의 피연산자 비트가 모두 1일 때만 1을 반환한다. 이러한 비트 AND 연산자는 두 개의 피연산자를 가지는 이항 연산자다.
int x = 7; // 00000000 00000000 00000000 00000111
int y = 10; // 00000000 00000000 00000000 00001010
printf("%d", x & y); // 00000000 00000000 00000000 00000010 : 2
2비트 OR 연산자
- 비트 OR 연산자는 두 개의 피연산자 비트 중 하나라도 1일 때는 1을 반환한다. 이러한 비트 OR 연산자는 두 개의 피연산자를 가지는 이항 연산자다.
int x = 7; // 00000000 00000000 00000000 00000111
int y = 10; // 00000000 00000000 00000000 00001010
printf("%d", x | y); // 00000000 00000000 00000000 00001111 : 15
// 15비트 XOR 연산자
- XOR 연산이란 배타적 논리합(exclusive OR)이라고도 불리며, 두 개의 피연산자 중 하나만이 1일 때 1을 반환한다. 이러한 성질을 이용하면 비트 NOT 연산자는 모든 비트를 반전시키지만, 비트 XOR 연산자는 지정한 비트만을 반전시킬 수 있다.
- 즉 비트가 1로 설정된 비트와 XOR 연산을 한 비트만이 반전되므로 반전될 비트를 직접 지정할 수 있게 됩니다. 이러한 비트 XOR 연산자는 두 개의 피연산자를 가지는 이항 연산자다.
int x = 7; // 00000000 00000000 00000000 00000111
int y = 10; // 00000000 00000000 00000000 00001010
printf("%d", x ^ y); // 00000000 00000000 00000000 00001101 : 13
// 13비트 시프트 연산자
- 비트 시프트(shift) 연산자는 비트 이동 연산자라고도 하며, 지정한 수만큼 모든 비트를 전부 좌우로 이동시킨다.
왼쪽 시프트 연산자
- 왼쪽 시프트 연산자(<<, left shift)는 지정한 수만큼 피연산자의 모든 비트를 전부 왼쪽으로 이동시킨다.
- 이렇게 왼쪽으로 모든 비트를 이동시키면, 맨 왼쪽의 비트는 지정된 수만큼 자동으로 버려지게 된다. 그리고 왼쪽으로 이동된 수만큼 비게 되는 오른쪽 비트에는 자동으로 0이 채워진다.
피연산자<<이동할비트수- 아래 예제에서 -1을 2비트만큼 왼쪽으로 이동한 결괏값은 -4가 되며, 3비트만큼 왼쪽으로 이동한 결괏값은 -8이 된다. 즉, 왼쪽 시프트 연산으로 1비트씩 모든 비트를 이동시킬 때마다 피연산자의 값은 두 배씩 증가하게 되는 걸 알 수 있다.
- 이러한 특징을 이용하여 속도가 다소 느린 산술 곱셈 연산을 왼쪽 시프트 연산으로 대체할 수 있다.
int x = -1; // 11111111 11111111 11111111 11111111
int y = x<<2; // 왼쪽으로 2비트만큼 이동시킴.
int z = x<<3; // 왼쪽으로 3비트만큼 이동시킴.
printf("%d\n", y); // 11111111 11111111 11111111 11111100 : -4
printf("%d", z); // 11111111 11111111 11111111 11111000 : -8
// -4
// -8오른쪽 시프트 연산자
- 오른쪽 시프트 연산자(>>, right shift)는 지정한 수만큼 피연산자의 모든 비트를 전부 오른쪽으로 이동시킨다.
- 이렇게 오른쪽으로 모든 비트를 이동시키면 맨 오른쪽의 비트는 지정된 수만큼 자동으로 버려지게 된다. 그리고 오른쪽으로 이동된 수만큼 비게 되는 왼쪽 비트에는 자동으로 0이 채워진다.
피연산자>>이동할비트수- 이때 오른쪽 시프트 연산은 왼쪽 시프트 연산과는 달리 시스템마다 약간의 차이가 발생하게 된다. 일부 시스템에서는 최상위 부호 비트(MSB)까지 시프트 연산의 대상이 되기도 하지만, 일부 시스템에서는 최상위 부호 비트는 시프트 연산의 대상에서 제외하기도 하기 때문이다. 따라서 최상위 부호 비트가 중요한 의미를 가지는 부호있는 정수에 대해서는 가급적 시프트 연산을 하지 않는 것이 좋다.
- 현재 대부분의 시스템에서는 최상위 부호 비트(MSB)를 시프트 연산의 대상에서 제외하고 있다.
- 아래 예제에서 -8을 2비트만큼 오른쪽으로 이동한 결괏값은 -2가 되며, 3비트만큼 오른쪽으로 이동한 결괏값은 -1이 된다. 즉, 오른쪽 시프트 연산으로 1비트씩 모든 비트를 이동시킬 때마다 피연산자의 값은 두 배씩 감소하게 되는 걸 알 수 있다. 이러한 특징을 이용하여 속도가 다소 느린 산술 나눗셈 연산을 오른쪽 시프트 연산으로 대체할 수 있습니다.
int x = -8; // 11111111 11111111 11111111 11111000
int y = x>>2; // 오른쪽으로 2비트만큼 이동시킴.
int z = x>>3; // 오른쪽으로 3비트만큼 이동시킴.
printf("%d\n", y); // 11111111 11111111 11111111 11111110 : -2
printf("%d", z); // 11111111 11111111 11111111 11111111 : -1
// -2
// -1
정수의 표현
- 컴퓨터에서 정수를 표현하는 방법은 크게 부호없는 정수와 부호있는 정수로 나누어 생각할 수 있다.
- 부호없는 정수를 표현할 때에는 단지 해당 정수 크기의 절댓값을 2진수로 변환하여 표현하면 된다. 하지만 문제는 부호있는 정수에서 음수를 표현하는 방법에 있다.
음수의 표현
부호 비트와 절댓값 방법
- 부호 비트와 절댓값 방법은 최상위 1비트로 부호를 표현하고, 나머지 비트로 해당 정수의 절댓값을 표현하는 방법이다. 이 방법을 사용하면 최상위의 1비트가 부호를 표현하기 위해 사용되어 표현할 수 있는 절댓값의 범위는 절반으로 줄어든다. 그러나 음수를 표현할 수 있으므로, 총 표현할 수 있는 크기는 거의 비슷해진다. 하지만 이 방법으로 음수를 표현하면 +0과 -0이 따로 존재하게 됩니다.
1의 보수법
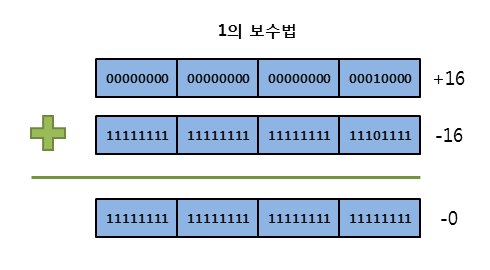
- 1의 보수법은 해당 양수의 모든 비트를 반전하여 음수를 표현하는 방법이다. 이 방법을 사용하면 음수를 비트 NOT 연산만으로 표현할 수 있어서 연산이 매우 간단해진다. 하지만 1의 보수법은 부호 비트와 절댓값 방법과 같이 +0과 -0이 따로 존재하는 문제점을 가진다.

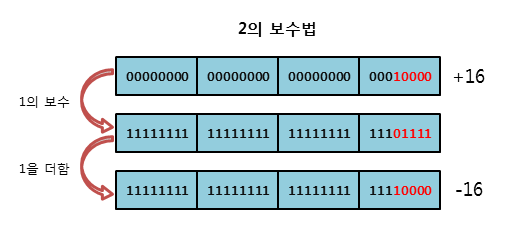
2의 보수법
- 2의 보수법은 해당 양수의 모든 비트를 반전한 1의 보수에 1을 더하여 음수를 표현하는 방법이다. 이 방법은 앞서 살펴본 방법이 모두 두 개의 0을 가지는 문제점(+0과 -0)을 해결하기 위해 고안되었다.
- 이 방법을 사용하면 -0은 2의 보수를 구하는 과정에서 최상위 비트를 초과한 오버플로우가 발생하여 +0이 된다. 따라서 2의 보수법에서는 단 하나의 0만이 존재하게 된다. 이 때문에 현재 대부분의 시스템에서는 모두 2의 보수법으로 음수를 표현하고 있다.
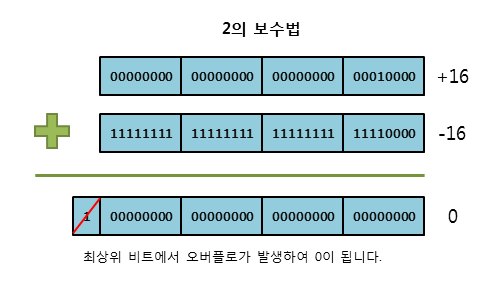
실수의 표현 방식
- 컴퓨터에서 실수를 표현하는 방법은 정수에 비해 훨씬 복잡하다. 왜냐하면 컴퓨터에서는 실수를 정수와 마찬가지로 2진수로만 표현해야 하기 때문이다.
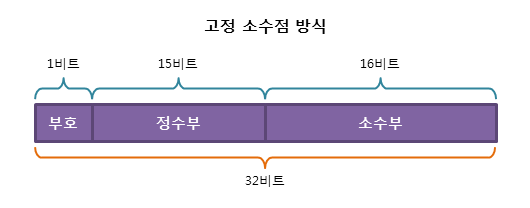
고정 소수점(fixed point) 방식
- 실수는 보통 정수부와 소수부로 나눌 수 있다. 따라서 실수를 표현하는 가장 간단한 방식은 소수부의 자릿수를 미리 정해 놓고, 고정된 자릿수로 소수를 표현하는 것이다.
- 32비트 실수를 고정 소수점 방식으로 표현하면 다음과 같다. 하지만 이 방식은 정수부와 소수부의 자릿수가 크지 않으므로, 표현할 수 있는 범위가 매우 적다는 단점이 있다.
부동 소수점(floating point) 방식
- 실수는 보통 정수부와 소수부로 나누지만, 가수부와 지수부로 나누어 표현할 수도 있다.
- 부동 소수점 방식은 이렇게 하나의 실수를 가수부와 지수부로 나누어 표현하는 방식이다.
- 앞서 살펴본 고정 소수점 방식은 제한된 자릿수로 인해 표현할 수 있는 범위가 매우 작습지만 부동 소수점 방식은 다음 수식을 사용하여 매우 큰 실수까지도 표현할 수 있게 된다. 따라서 현재 대부분의 시스템에서는 부동 소수점 방식으로 실수를 표현하고 있다.
EEE 부동 소수점 방식
- 현재 사용되고 있는 부동 소수점 방식은 대부분 IEEE 754 표준을 따르고 있다.
- 32비트의 float형 실수와 64비트의 double형 실수를 IEEE 부동 소수점 방식으로 표현하면 다음과 같다.



부동 소수점 방식의 오차
- 부동 소수점 방식을 사용하면 고정 소수점 방식보다 훨씬 더 많은 범위까지 표현할 수 있다. 하지만 부동 소수점 방식에 의한 실수의 표현은 항상 오차가 존재한다는 단점을 가지고 있다.
- 부동 소수점 방식에서의 오차는 앞서 살펴본 공식에 의해 발생한다. 이 공식을 사용하면 표현할 수 있는 범위는 늘어나지만, 10진수를 정확하게 표현할 수는 없게 되기 때문이다. 따라서 컴퓨터에서 실수를 표현하는 방법은 정확한 표현이 아닌 언제나 근사치를 표현할 뿐임을 항상 명심해야 한다.
int i;
float sum = 0.1;
for (i = 0; i < 1000; i++) {
sum += 0.1;
}
printf("0.1을 1000번 더한 합계는 %f입니다.\n", sum);
// 0.1을 1000번 더한 합계는 100.099045입니다.- 위의 예제에서 0.1을 1000번 더한 합계는 정확히 100이 되어야 하지만, 실제로는 100.099045가 출력된다. 이처럼 컴퓨터에서 실수를 가지고 수행하는 모든 연산에는 언제나 작은 오차가 존재하게 된다. 이것은 C언어에서 뿐만 아니라 모든 프로그래밍 언어에서 발생하는 기본적인 문제다.
Reference
728x90
반응형
'Language > C' 카테고리의 다른 글
| [C] C언어 컴파일 - 헤더 파일, 분할 컴파일, 조건부 컴파일 (0) | 2026.06.09 |
|---|---|
| [C] C언어 선행처리 - 선행처리기, 매크로 함수 (1) | 2026.06.09 |
| [C] C언어 입력과 출력 - 콘솔, 파일, 함수 (1) | 2026.06.08 |
| [C] C언어 구조체 - 개념, 포인터, 활용, 공용체와 열거체 (0) | 2026.06.08 |
| [C] C언어 문자와 문자열 - 입출력, 함수 (0) | 2026.06.07 |