반응형
머신러닝 대표 알고리즘
- 머신러닝은 학습하려는 문제의 유형에 따라 크게 지도/비지도/강화 학습으로 나눌 수 있고, 각 학습 방법들은 상황에 맞는 다양한 알고리즘을 사용하여 구현할 수 있다.
서포트 벡터 머신(Support Vector Machine, SVM)
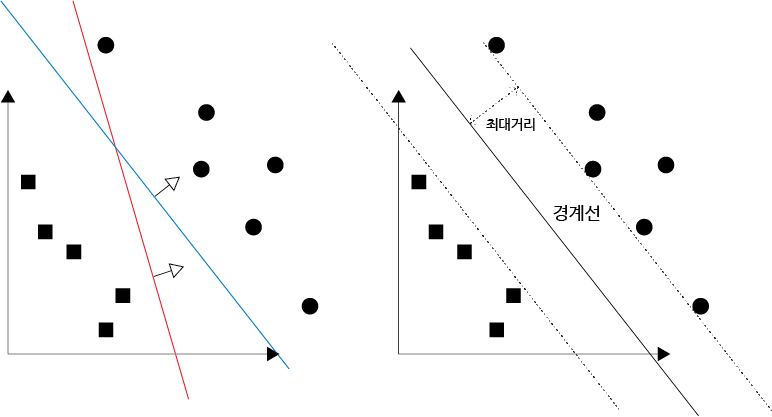
- SVM은 지도 학습 중 분류 모델에서 가장 많이 사용되는 알고리즘으로, 주로 다루려는 데이터가 2개의 그룹으로 분류될 때 많이 사용된다.
- SVM은 학습 데이터가 벡터 공간에 위치하고 있다고 생각하며 학습 데이터의 특징 수를 조절함으로써 2개의 그룹을 분류하는 경계선을 찾고, 이를 기반으로 패턴을 인식하는 방법이다.
- 두 그룹을 분류하는 경계선은 최대한 두 그룹에서 멀리 떨어져 있는 경계선을 구하게 되며, 이는 두 그룹과의 거리를 최대로 만드는 것이 나중에 입력된 데이터를 분류할 때 더 높은 정확도를 얻을 수 있기 때문이다.
의사 결정 나무(Decision tree)
- 귀납적 추론을 기반으로 하는 의사 결정 트리는 데이터를 분석하여 이들 사이에 존재하는 패턴을 시각적이고 명시적인 방법으로 보여주는 지도 학습 알고리즘 중 하나로, 분류나 회귀 모델 둘 다에 적용할 수 있다.
- 의사 결정 트리의 기본 개념은 질문을 던져 답을 얻음으로써 그 대상을 좁혀나가는 개념으로, 다른 알고리즘에 비해 쉽게 활용할 수 있는 장점이 있다.
- 의사 결정 트리는 환자의 과거 진료 기록을 토대로 증상을 유추하거나 대출을 위한 신용평가, 고객의 소비 행동 예측 등 다양한 분야에서 활용되고 있다.
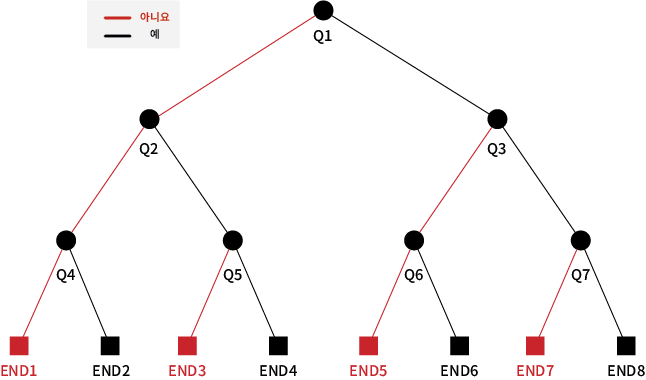
- 목표 속성과 이와 관계있는 후보 속성들을 선택한다.
- 데이터를 분석하는 목적과 자료 구조에 따라 적절한 분리 기준과 정지 규칙을 정하여 트리 구조를 작성한다.
- 완성된 트리 구조에서 정확도를 떨어뜨리는 속성은 제거한다. - 가지치기(Pruning)
정지 규칙이란 더 이상 분리가 일어나지 않고 현재 노드가 잎 노드(Leaf Node)가 되도록 하는 여러 규칙들을 의미한다.
K-means 군집화(K-means Clustering)
- K-means 군집화는 비지도 학습의 군집화 중에서도 분할 기반(Partition-based) 군집화에 속하는 방법으로, 가장 간단한 비지도 학습 알고리즘 중 하나다.
- K-means 군집화는 알고리즘의 개념이 매우 직관적이며, 학습을 위해 수행해야 할 데이터의 계산의 양이 매우 적다는 장점을 가진다.
- 하지만 모양이 구형(Spherical)이 아닌 군집에 대해서는 정확도가 떨어지며, 동떨어져 있는 데이터인 이상값(Outlier)에 매우 민감하고, 또 맨 처음에 결정한 군집의 개수인 K에 따라 결과값이 완전히 달라지는 경우도 발생하는 단점이 있다.
- K-means 군집화는 시장 분석, 이미지 작업, 지질 통계학, 천문학 등 광범위한 분야에서 활용되고 있으며, 특히 다른 알고리즘을 수행하기 전에 학습 데이터를 전처리(Pre-processing)하는 용도로도 많이 사용되고 있다.

- 총 n개의 데이터를 학습할 경우 n보다 작거나 같은 k를 결정한 후, 임의의 중심점을 k개 설정한다.
- 모든 학습 데이터는 k개의 중심점까지의 거리를 각각 계산한 후에 가장 가까운 중심점을 자신이 속한 군집의 중심점이라고 저장한다.
- 각 군집에 속한 데이터에 저장된 중심점 좌표값들의 평균을 구한 뒤 이를 바탕으로 해당 군집의 새로운 중심점을 설정한다.
- 새롭게 설정된 중심점을 가지고 2단계와 3단계를 다시 반복한다.
- 모든 학습 데이터가 자신이 속한 군집을 변경하지 않는 경우 학습을 완료한다.
Reference
반응형
'Data > Ai' 카테고리의 다른 글
| 딥러닝의 분류 - 심층/합성곱/순환 신경망, 제한 볼츠만, 심층Q (0) | 2023.06.18 |
|---|---|
| 딥러닝의 개념과 동작 방식 - 인공신경망 (0) | 2023.06.18 |
| 머신러닝의 분류 - 지도와 비지도, 강화 학습 (0) | 2023.06.18 |
| 머신러닝의 개념과 동작 방식 - 벡터와 특징 추출 (0) | 2023.06.18 |
| 인공지능이란 - 머신러닝과 딥러닝의 개념과 차이점 (0) | 2023.06.18 |